Many popular Open Source products use Algolia DocSearch to power their real-time search features, however, it's a less appealing product for commercial products which is a paid service with a per request pricing model that made it difficult to determine what costs would be in the long run.
We discovered Typesense as an appealing alternative which offers simple cost-effective cloud hosting but even better, they also have an easy to use open source option for self-hosting or evaluation. Given its effortless integration, simplicity-focus and end-user UX, it quickly became our preferred way to navigate docs.servicestack.net.
To make it easier to adopt Typesense's amazing OSS Search product we've documented the approach we use to create and deploy an index of our site automatically using GitHub Actions that you could also utilize in your Razor Press websites.
Documentation search is a common use case which Typesense caters for with their typesense-docsearch-scraper - a utility designed to easily scrape a website and post the results to a Typesense server to create a fast searchable index.
Self hosting option
We recommend using running their easy to use Docker image to run an instance of their Typesense server, which you can run in a t2.small AWS EC2 instance or in a Hetzner Cloud VM for a more cost effective option.
Trying it locally, we used the following commands to spin up a local Typesense server ready to scrape out docs site.
mkdir /tmp/typesense-data
docker run -p 8108:8108 -v/tmp/data:/data typesense/typesense:0.21.0 \
--data-dir /data --api-key=<temp-admin-api-key> --enable-cors
To check that the server is running, we can open a browser at /health and we get back 200 OK with ok: true.
The Typesense server has a REST API which can be used to manage the indexes you create. Or if you use their cloud offering, you can use their web dashboard to monitor and manage your index data.
Populating the index
With your local server is running, you can scrape your docs site using the typesense-docsearch-scraper. This needs some configuration to tell the scraper:
- Where the Typesense server is
- How to authenticate with the Typesense server
- Where the docs website is
- Rules for the scraper to follow extracting information from the docs website
These pieces of configuration come from 2 sources. A .env file related to the Typesense server information and a .json file related to what site will be getting scraped.
With a Typesense running locally on port 8108, we configure the .env file with the following information:
TYPESENSE_API_KEY=${TYPESENSE_API_KEY}
TYPESENSE_HOST=localhost
TYPESENSE_PORT=8108
TYPESENSE_PROTOCOL=http
Next, we have to configure the .json config for the scraper.
The typesense-docsearch-scraper has an example of this
config in their repository.
The default selectors will need to match the your websites HTML, which for Razor Press sites can start with the configuration, updated with your website domains:
{
"index_name": "typesense_docs",
"allowed_domains": ["docs.servicestack.net"],
"start_urls": [
{
"url": "https://docs.servicestack.net/"
}
],
"selectors": {
"default": {
"lvl0": "h1",
"lvl1": ".content h2",
"lvl2": ".content h3",
"lvl3": ".content h4",
"lvl4": ".content h5",
"text": ".content p, .content ul li, .content table tbody tr"
}
},
"scrape_start_urls": false,
"strip_chars": " .,;:#"
}
With both the configuration files ready to use, we can run the scraper itself. The scraper is also available using the
docker image typesense/docsearch-scraper which we can pass our configuration to, using the following command:
docker run -it --env-file typesense-scraper.env \
-e "CONFIG=$(cat typesense-scraper-config.json | jq -r tostring)" \
typesense/docsearch-scraper
Here -i is used to reference a local --env-file and use cat and jq used to populate the CONFIG environment variable
with the .json config file.
Docker networking
We had a slight issue here since the scraper itself is running in Docker via WSL and localhost doesn't resolve to our
host machine to find the Typesense server also running in Docker.
Instead we need to point the scraper to the Typesense server using the Docker local IP address space of 172.17.0.0/16
for it to resolve without additional configuration.
We can see in the output of the Typesense server that it is running using 172.17.0.2. We can swap the localhost
with this IP address after which we see the communication between the servers flowing:
DEBUG:typesense.api_call:Making post /collections/typesense_docs_1635392168/documents/import
DEBUG:typesense.api_call:Try 1 to node 172.17.0.2:8108 -- healthy? True
DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): 172.17.0.2:8108
DEBUG:urllib3.connectionpool:http://172.17.0.2:8108 "POST /collections/typesense_docs_1635392168/documents/import HTTP/1.1" 200 None
DEBUG:typesense.api_call:172.17.0.2:8108 is healthy. Status code: 200
> DocSearch: https://docs.servicestack.net/azure 22 records)
DEBUG:typesense.api_call:Making post /collections/typesense_docs_1635392168/documents/import
DEBUG:typesense.api_call:Try 1 to node 172.17.0.2:8108 -- healthy? True
DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): 172.17.0.2:8108
DEBUG:urllib3.connectionpool:http://172.17.0.2:8108 "POST /collections/typesense_docs_1635392168/documents/import HTTP/1.1" 200 None
The scraper crawls the docs site following all the links in the same domain to get a full picture of all the content of our docs site. This takes a minute or so, and in the end we can see in the Typesense sever output that we now have committed_index: 443.
_index: 443, applying_index: 0, pending_index: 0, disk_index: 443, pending_queue_size: 0, local_sequence: 44671
I20211028 03:39:40.402626 328 raft_server.h:58] Peer refresh succeeded!
Searching content
After you have a Typesense server with an index full of content, you'll want to be able to use it to search your docs site.
You can query the index using curl which needs to known 3 key pieces of information:
- Collection name, eg
typesense_docs - Query term,
?q=test - What to query,
&query_by=content
curl -H 'x-typesense-api-key: <apikey>' \
'http://localhost:8108/collections/typesense_docs/documents/search?q=test&query_by=content'
The collection name and query_by come from how the scraper was configured. The scraper was posting data to the
typesense_docs collection and populating various fields, eg content.
Which as it returns JSON can be easily queried in JavaScript using fetch:
fetch('http://localhost:8108/collections/typesense_docs/documents/search?q='
+ encodeURIComponent(query) + '&query_by=content', {
headers: {
// Search only API key for Typesense.
'x-typesense-api-key': 'TYPESENSE_SEARCH_ONLY_API_KEY'
}
})
In the above we have also used a different name for the API key token, this is important since the --api-key specified to the running Typesense server is the admin API key. You don't want to expose this to a browser client since they will have the ability to create,update and delete your collections or documents.
Instead we want to generate a "Search only" API key that is safe to share on a browser client. This can be done using the Admin API key and the following REST API call to the Typesense server.
curl 'http://localhost:8108/keys' -X POST \
-H "X-TYPESENSE-API-KEY: ${TYPESENSE_API_KEY}" \
-H 'Content-Type: application/json' \
-d '{"description": "Search only","actions": ["documents:search"],"collections":["*"]}'
Now we can share this generated key safely to be used with any of our browser clients.
Keeping the index updated
A problem that becomes apparent when running the scraper is that it increases the size of the index since it currently doesn't detect and update existing documents. It wasn't clear if this is possible to configure from the current scraper, but we needed a way to achieve the following goals:
- Update the search index automatically soon after docs have been changed
- Don't let the index grow too big to avoid manual intervention
- Have high uptime so documentation search is always available
Typesense server itself performs extremely well, so a full update from the scraper doesn't generate an amount of load. However, every additional scrape uses additional disk space and memory that will eventually require periodically resetting and repopulating the index.
One option is to switch to a new collection everytime the documentation is updated and delete the old collection, adopting a workflow that looks something like:
- Docs are updated
- Publish updated docs
- Create new collection, store new and old names
- Scrape updated docs
- Update client with new collection
- Delete old collection
However this would require orchestration across a number of GitHub Action workflows which we anticipated would be fragile and non-deterministic as to how long it will take to scrape, update, and deploy our changes.
Read-only Docker container
The approach we ended up adopting was to develop and deploy read only Typesense Docker images containing an immutable copy of the index data in it as part of the GitHub Action deployments.
In the case of Typesense, when it starts up, it reads from its data directory from disk to populate the index in
memory and since our index is small and only updates when our documentation is updated, we can simplify the management
of the index data by baking it into the docker image.
This has several key advantages.
- Disaster recovery doesn't need any additional data management.
- Shipping an updated index is a normal ECS deployment.
- Zero down time deployments.
- Index is of a fixed size once deployed.
Typesense Performance
Search on our documentation site is a very light workload for Typesense. Running as an ECS service on a 2 vCPU instance, the service struggled to get close to 1% whilst serving constant typeahead searching.
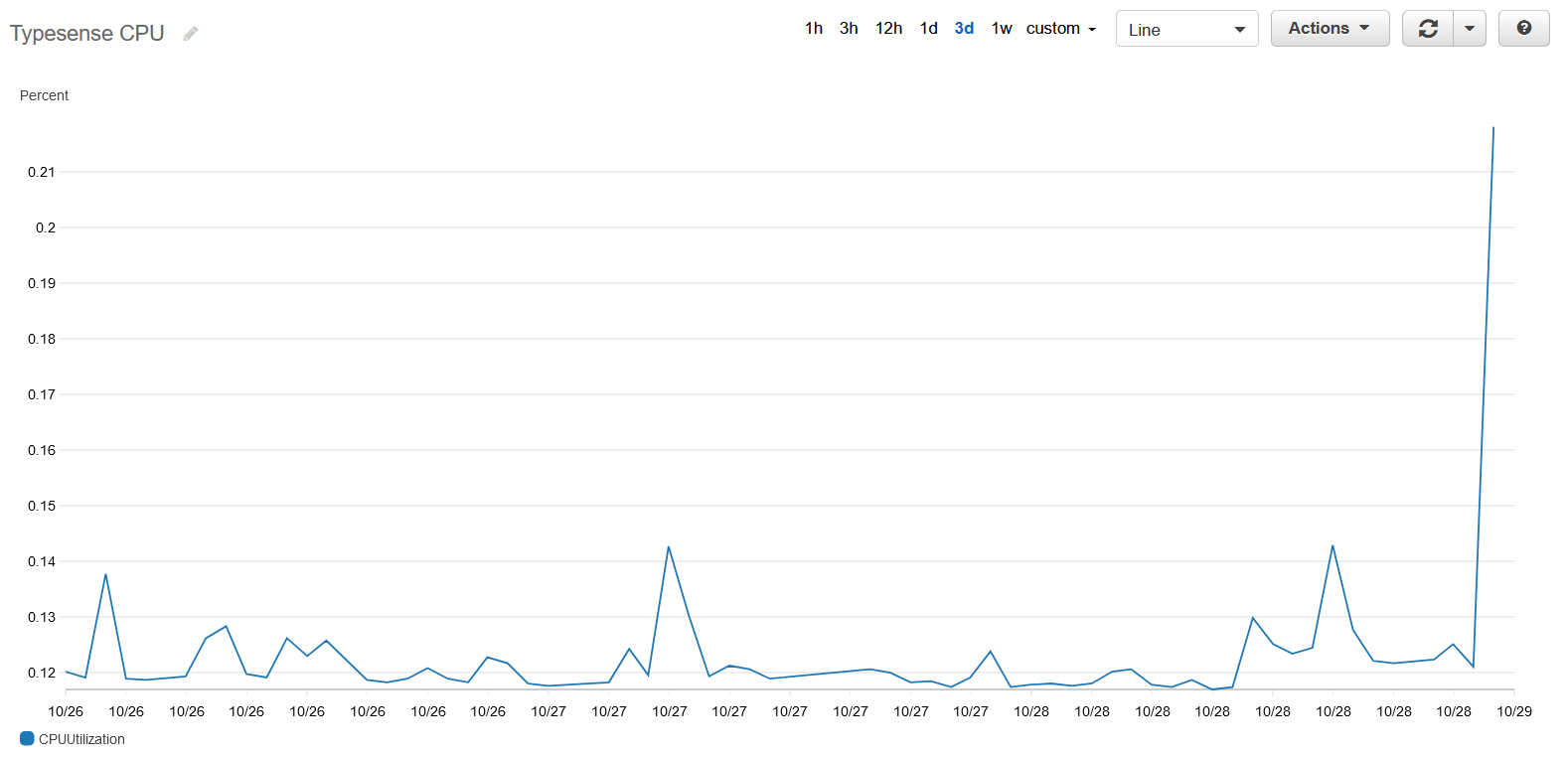
Since our docs site index is small (500 pages), the memory footprint is also tiny and stable at ~50MB or ~10% of the the service's soft memory limit.
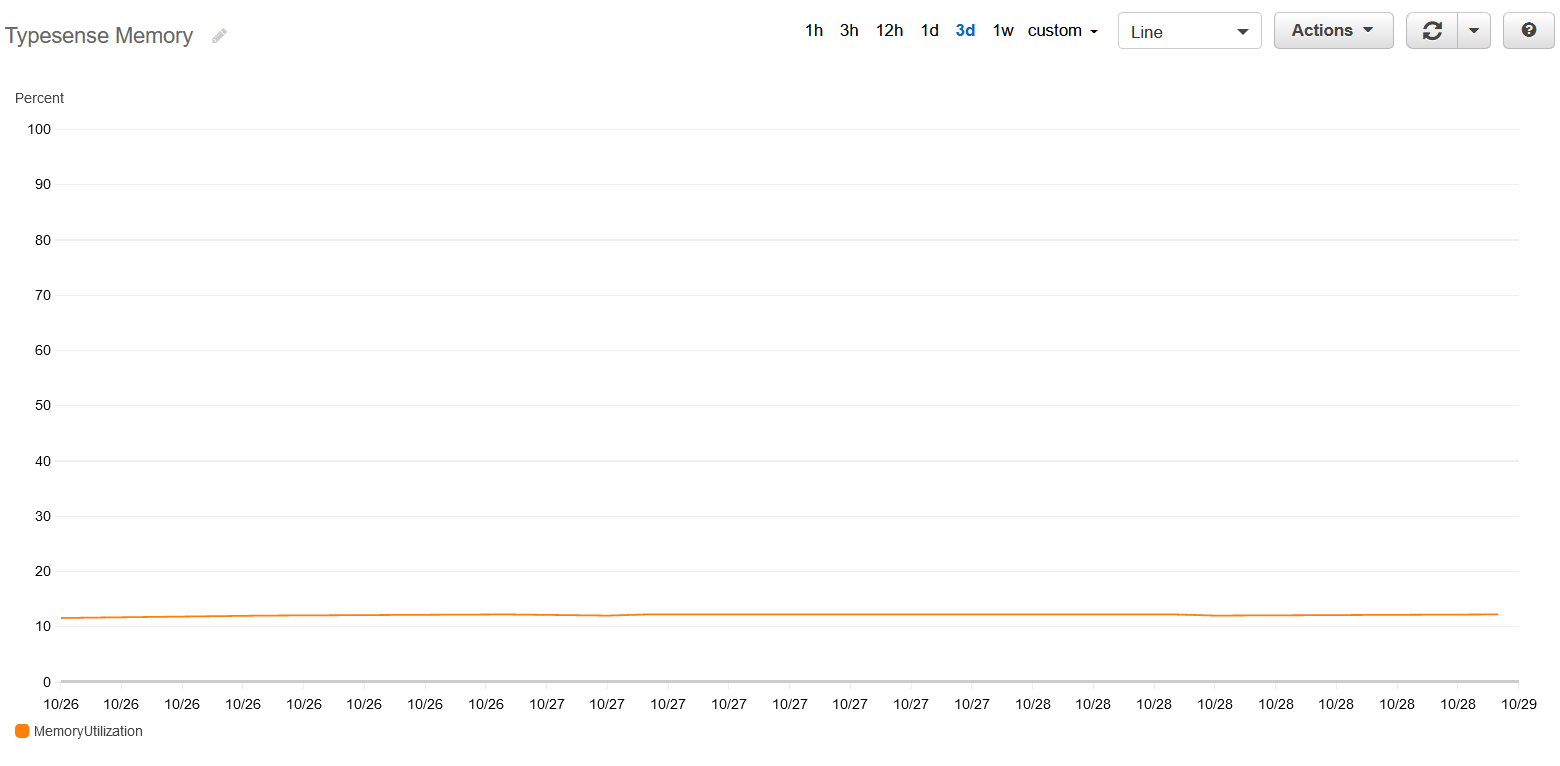
This means we will be able to host this using a single EC2 instance among various other or the ServiceStack hosted example applications and use the same deployment patterns we've shared in our GitHub Actions templates.
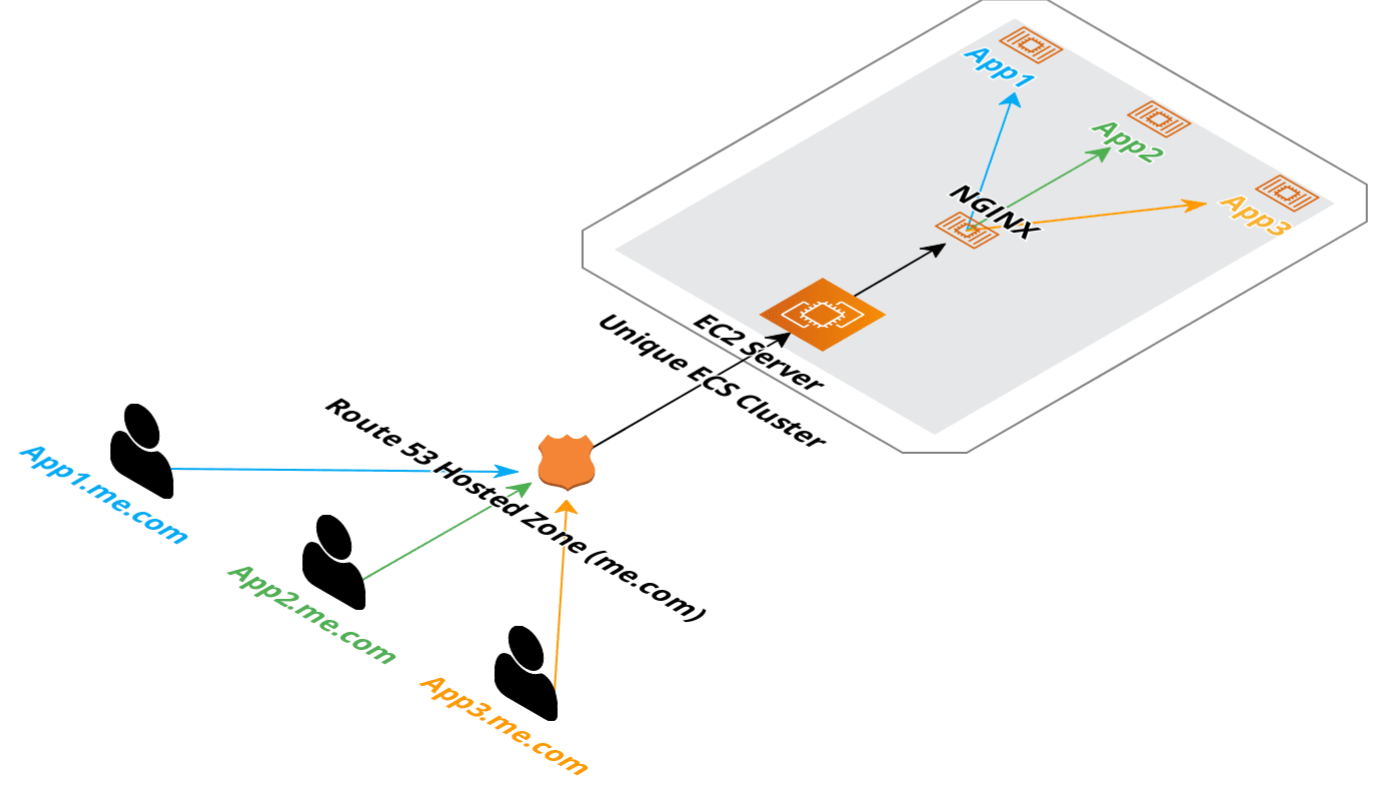
Whilst this approach of shipping an index along with the Docker image isn't practical for large or 'living' indexes, many small to medium-sized documentation sites would likely benefit from the simplified approach of deploying readonly Docker images.
GitHub Actions Workflow
To create our own Docker image for our search server we need to perform the following tasks in our GitHub Action:
- Run a local Typesense server in the GitHub Action using Docker
- Scrape our hosted docs populating the local Typesense server
- Copy the
datafolder of our local Typesense server duringdocker build
Which is done with:
mkdir -p ${GITHUB_WORKSPACE}/typesense-data
cp ./search-server/typesense-server/Dockerfile ${GITHUB_WORKSPACE}/typesense-data/Dockerfile
cp ./search-server/typesense-scraper/typesense-scraper-config.json typesense-scraper-config.json
envsubst < "./search-server/typesense-scraper/typesense-scraper.env" > "typesense-scraper-updated.env"
docker run -d -p 8108:8108 -v ${GITHUB_WORKSPACE}/typesense-data/data:/data \
typesense/typesense:0.21.0 --data-dir /data --api-key=${TYPESENSE_API_KEY} --enable-cors &
# wait for typesense initialization
sleep 5
docker run -i --env-file typesense-scraper-updated.env \
-e "CONFIG=$(cat typesense-scraper-config.json | jq -r tostring)" typesense/docsearch-scraper
Our Dockerfile then takes this data from the data folder during build.
FROM typesense/typesense:0.21.0
COPY ./data /data
To avoid updating our search client between updates we also want to use the same search-only API Key everytime
a new server is created. This can be achieved by specifying value in the POST command sent to the local Typesense server:
curl 'http://172.17.0.2:8108/keys' -X POST \
-H "X-TYPESENSE-API-KEY: ${TYPESENSE_API_KEY}" \
-H 'Content-Type: application/json' \
-d '{"value":<search-api-key>,"description":"Search only","actions":["documents:search"],"collections":["*"]}'
If you're interested in adopting a similar approach you can find the whole GitHub Action workflow in our search-index-update.yml workflow.
Search UI Dialog
After docs are indexed the only thing left to do is display the results. We set out to create a comparable UX to Algolia's doc search dialog which we've implemented in the Typesense.mjs Vue component which you can register as a global component in your app.mjs:
import Typesense from "./components/Typesense.mjs"
const Components = {
//...
Typesense,
}
Which renders as a Search Button that we've added next to our Dark Mode Toggle button in our Header.cshtml:
<div class="hidden sm:ml-6 sm:flex sm:items-center">
<typesense></typesense>
<dark-mode-toggle class="ml-2 w-10"></dark-mode-toggle>
</div>

The button also encapsulates the dialog component which uses Typesense REST API to query to our typesense instance:
fetch('https://search.docs.servicestack.net/collections/typesense_docs/documents/search?q='
+ encodeURIComponent(query.value)
+ '&query_by=content,hierarchy.lvl0,hierarchy.lvl1,hierarchy.lvl2,hierarchy.lvl3&group_by=hierarchy.lvl0', {
headers: {
// Search only API key for Typesense.
'x-typesense-api-key': 'TYPESENSE_SEARCH_ONLY_API_KEY'
}
})
This instructs Typesense to search through each documents content and h1-3 headings, grouping results by its page title. Refer to the Typesense API Search Reference to learn how to further fine-tune search results for your use-case.
Search Results
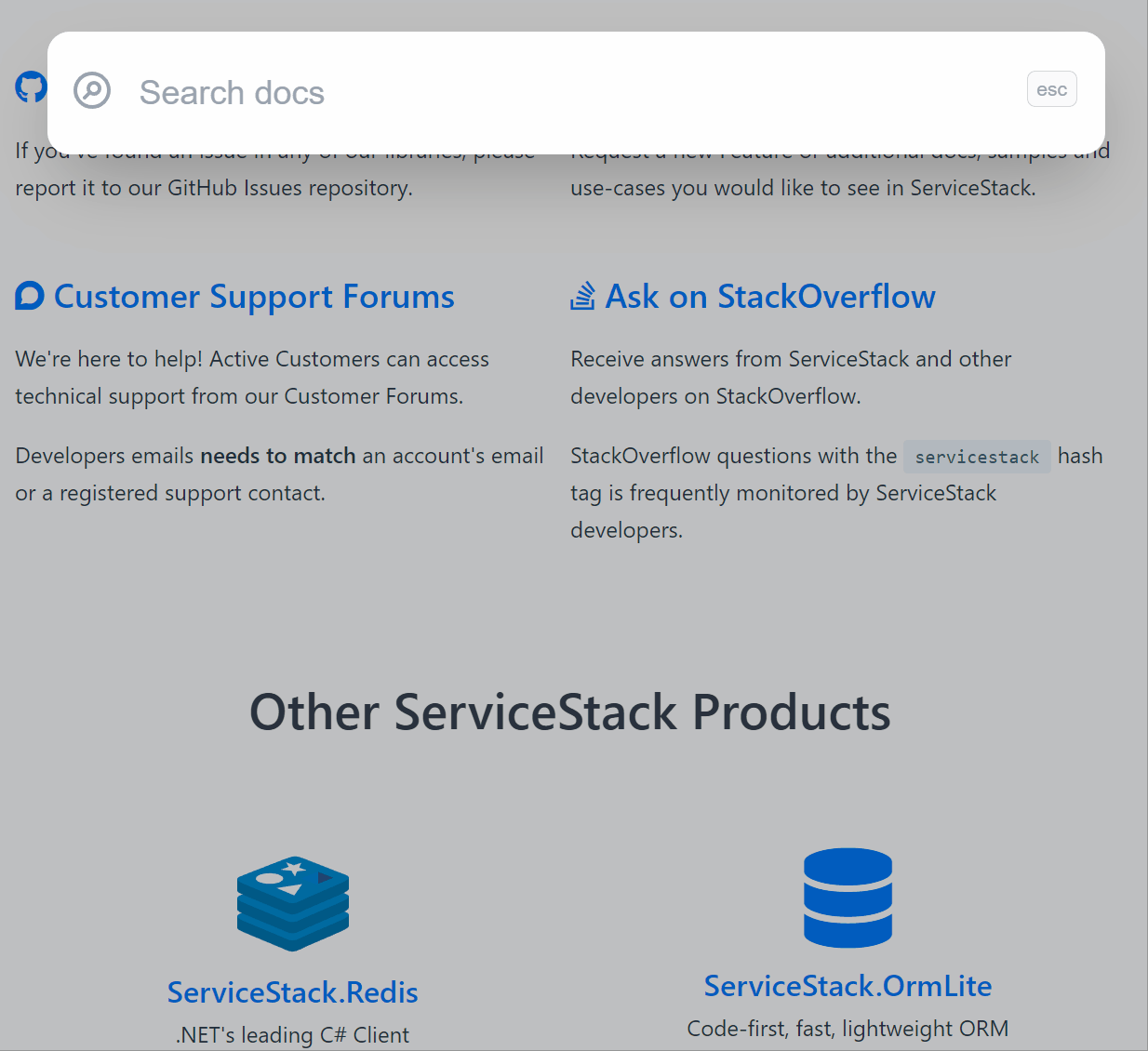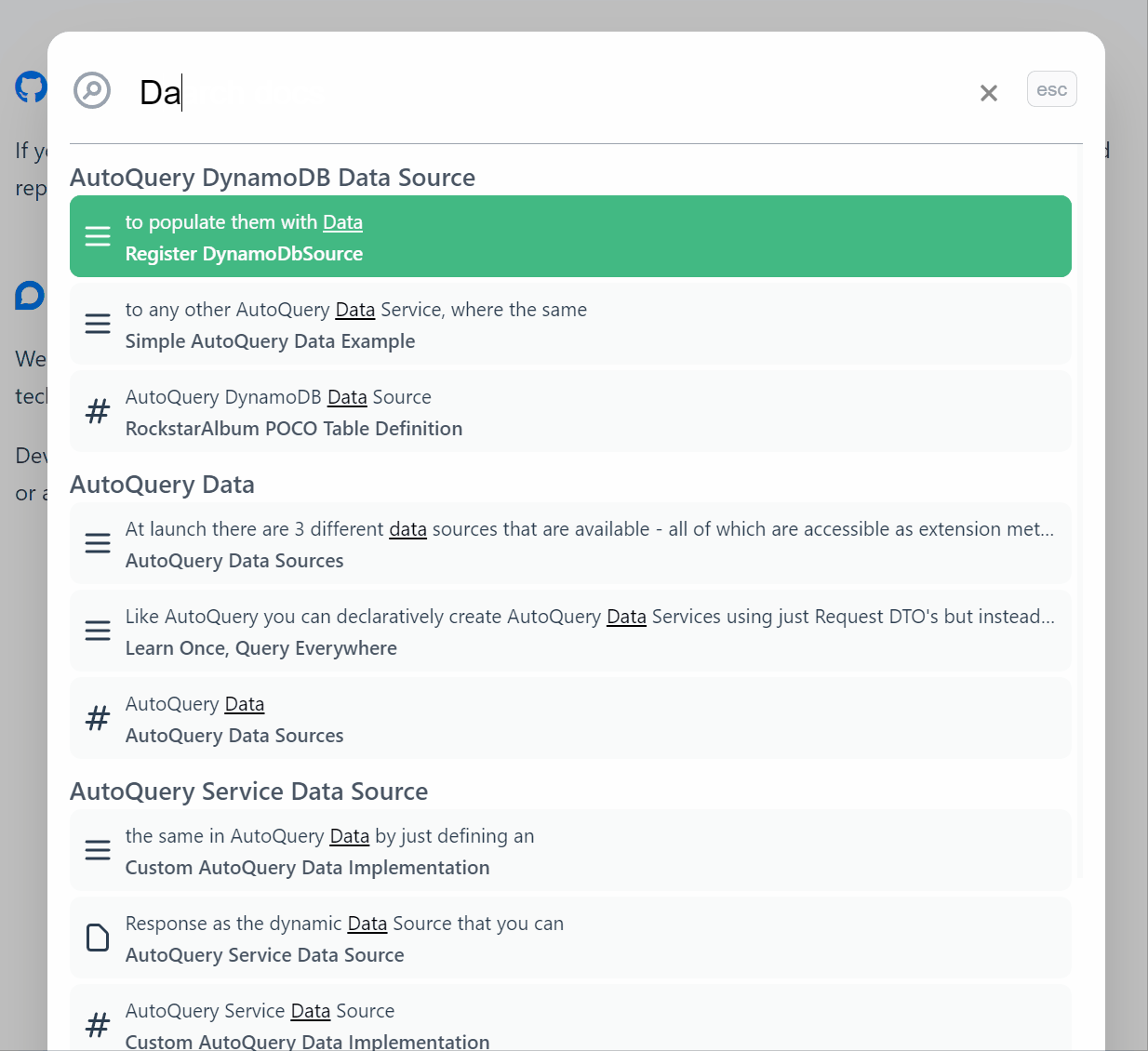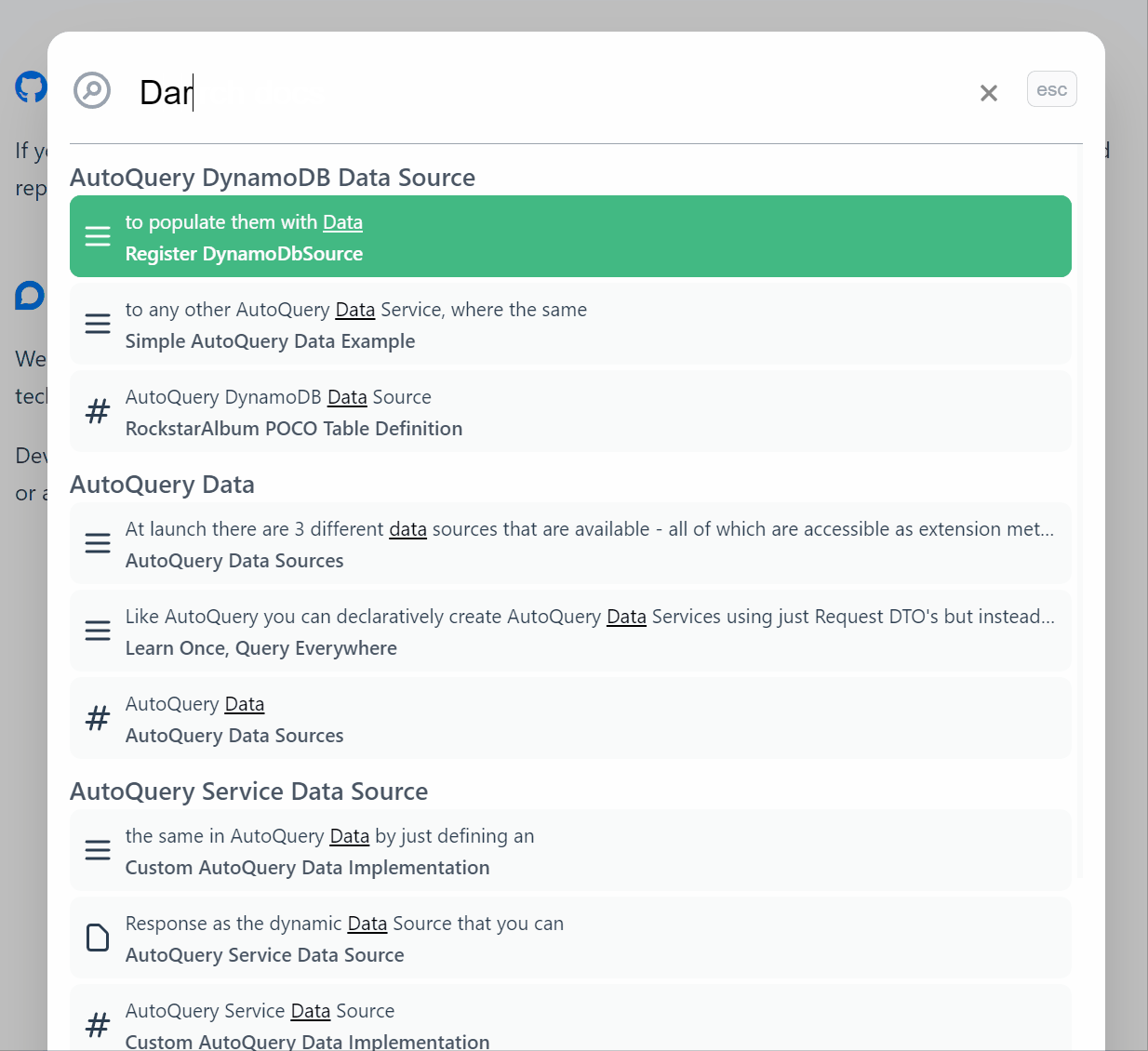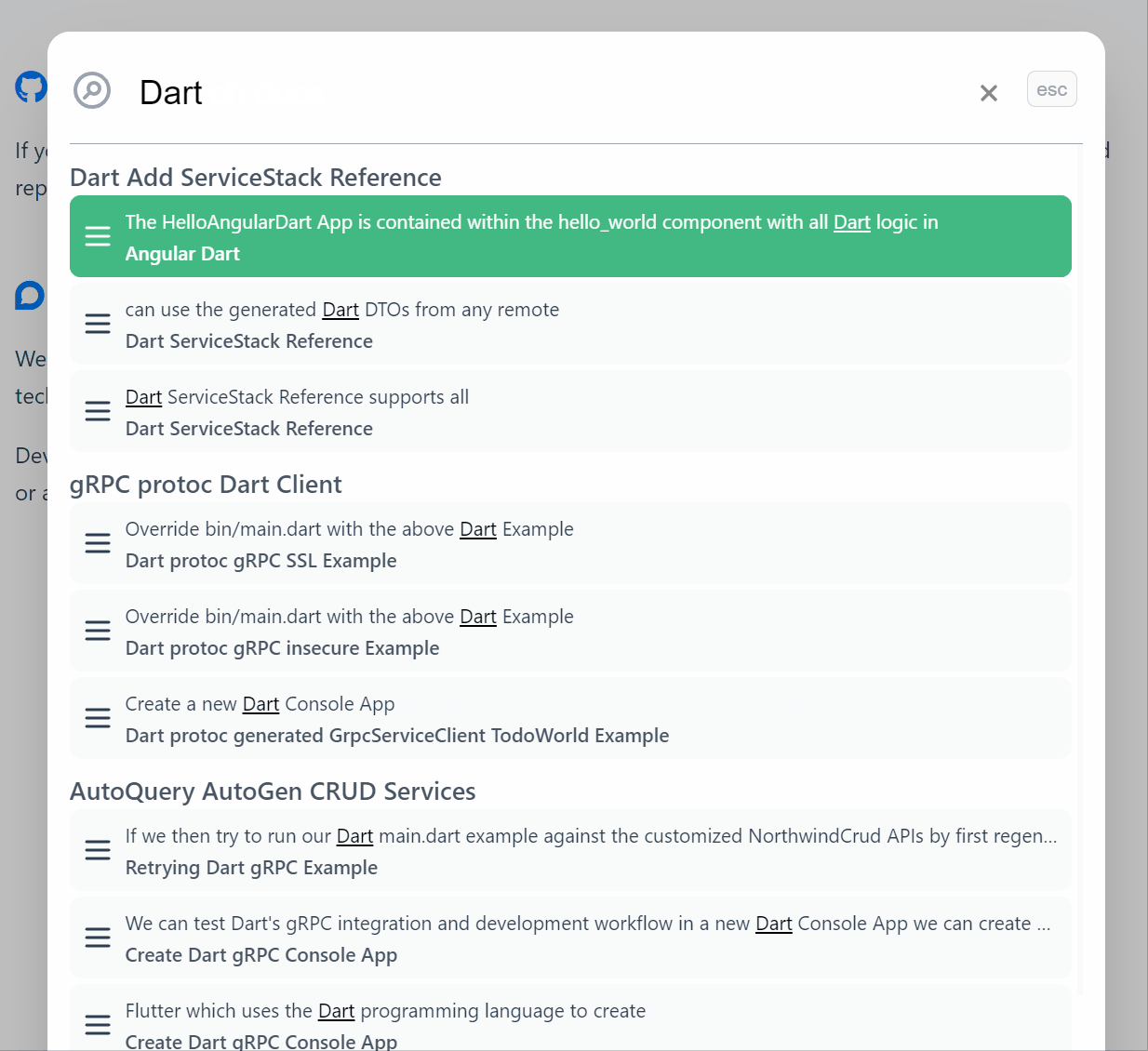
The results are excellent, see for yourself by using the search at the top right or
using Ctrl+K shortcut key on docs.servicestack.net.
It also does a great job handling typos and has quickly become the fastest way to navigate our extensive documentation that we hope also serves useful for implementing Typesense real-time search in your own documentation websites.